



























最近迷上了王者荣耀,但是水平太菜了,每次开局还得先看看技能介绍什么的,为了不坑大伙,干脆抓一份资料回来,放自己电脑上随用随查吧!!

工具:pycharm、python3.6、requests 库、scrapy 库和 selenium、 PhantomJS 库
目标 url 获取:http://pvp.qq.com/web201605/herolist.shtml 里有所有英雄的列表,抓包,并写入函数
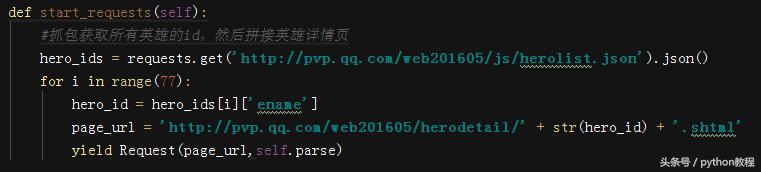
分析网页,先写 items.py,主要内容如下:
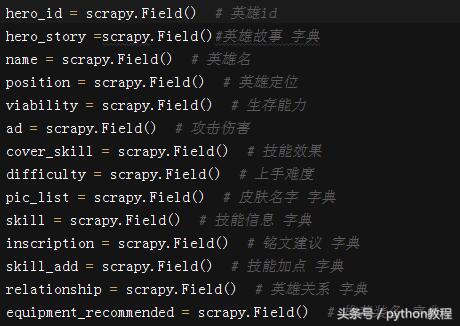
Pipelines.py 内容(最终文件为 json 格式):
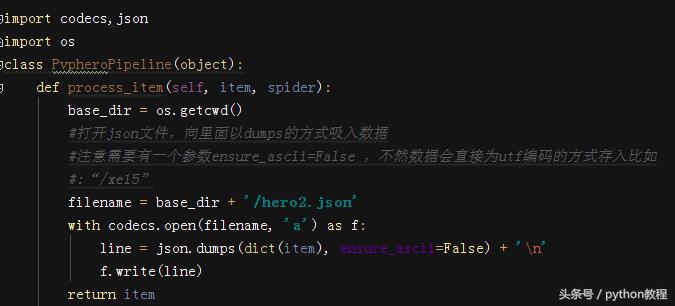
记得在 settings.py 里面将 ITEM_PIPELINES 打开,并设置 ROBOTSTXT_OBEY 为False(不打开不能保存文件,设置 robotstxt 是跳过网站 ROBOT 协议)
然后就是 spiders 文件下新建一个 hero.py,用来写我们的爬虫,抓取的内容较多,都已经在网页存在,比较简单,注意写入 items 时的格式就好
本次爬虫还有需要改进的地方
技能加点建议部分,是在渲染后写入的,没有能在网页源码中找到相应部分,没办法,用了 selenium+PhantomJS的方式抓取,希望有大神可以帮忙改进!
英雄故事部分,有的英雄详情页的英雄故事所在结构不同,导致出错不得已加了 try方法
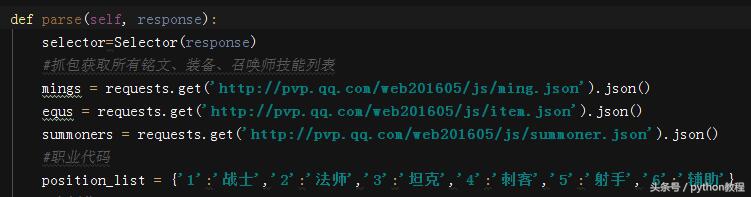
需要注意的还有一个地方,每一个英雄详情页面,召唤师技能、装备、铭文是单独一个 json字典,在网页中存在相应的 ID,先抓包然后在网页内匹配 id即可,而职业也是有相应的 id字段,先写到上面,后面调用,如下:

其他都很好匹配的,就一层抓取,直接上爬虫代码,因为截长图,效果不好,就分部分截取了,有兴趣的小伙伴可以找我要源码的 首先是导入模块部分
首先是导入模块部分
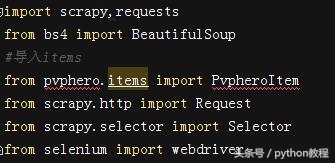
爬虫入口,有 77个英雄,所以直接写入循环获取每一个英雄的详情页
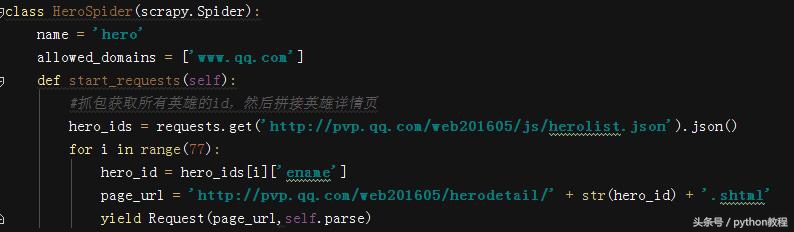
开始写解析函数,先将需要的字典抓包获取
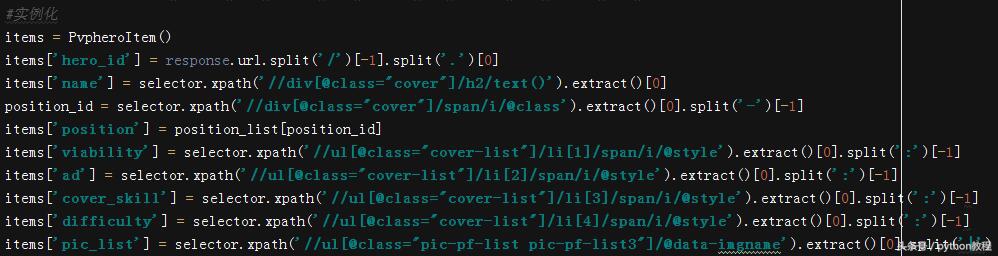
实例化 items,开始写入前几个字段
 技能信息和铭文建议部分
技能信息和铭文建议部分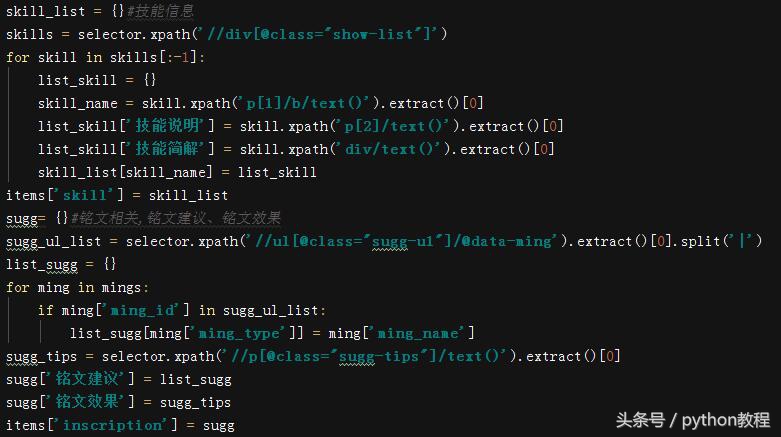
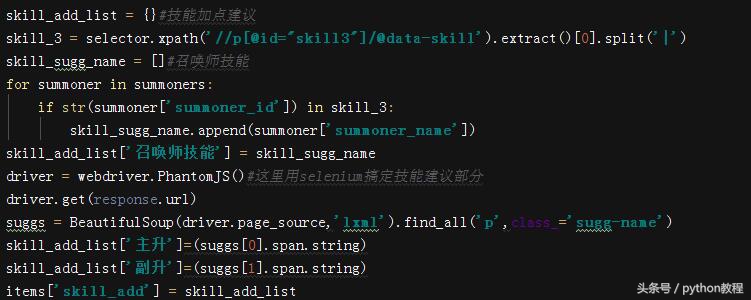
技能加点建议、召唤师技能建议部分,注意这里使用了模拟浏览器的方式获取
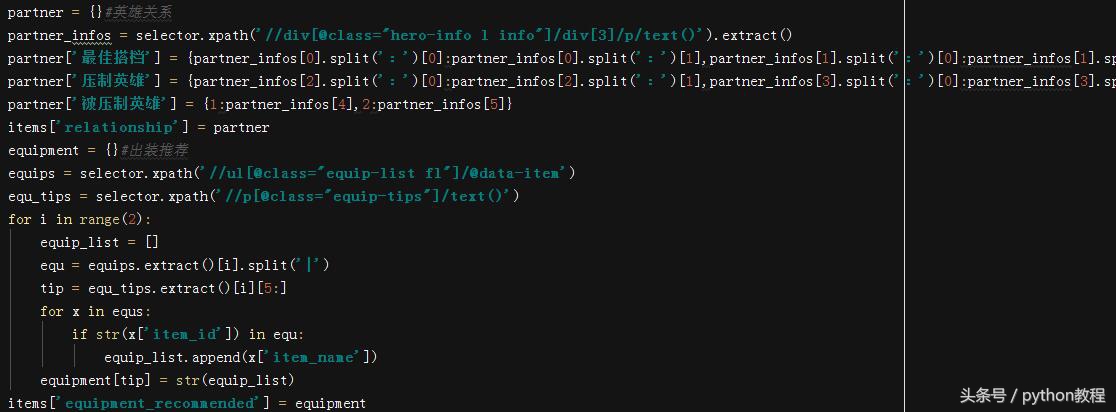
英雄关系和装备推荐部分,其中英雄关系部分其实是一段话,手工分开
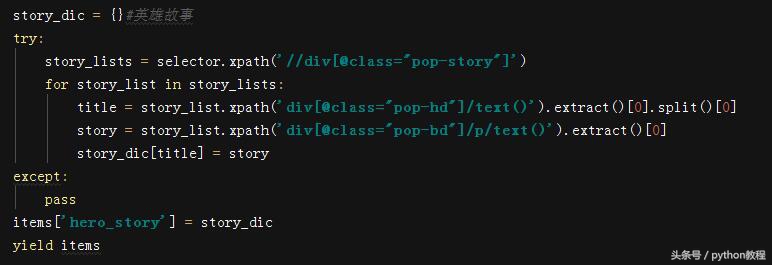
最后是英雄故事部分
运行结束后,生成的文件和解析后内容片段



到这里就完成了,有兴趣或者想要源码的小伙伴可以私信我:资料,获取联系方式,咱们一起学习进步哦!

不过在这之前,我们先来一把吧!!保证不坑~!






















 1
1







