































文章文字比较多,请耐心的阅读,你会受益匪浅!
【XIA篇】【XIA篇】【XIA篇】【XIA篇】【XIA篇】
你必须问一个问题“我如何设置 Kubernetes 集群?”你最终可能会从不同的搜索结果中得到不同的答案,这对初学者来说可能是压倒性的。Kubernetes 是一个复杂的系统,安装并妥善管理它并非易事。
然而,随着 Kubernetes 社区的扩展和成熟,出现了越来越多的用户友好工具。截至今天,根据您的要求,有很多选项可供选择:
- 如果您使用的是物理(裸机)服务器或虚拟机 (VM),Kubeadm 非常适合。
- 如果你在云环境中运行,kops 和 Kubespray 可以简化 Kubernetes 的安装,以及与云提供商的集成。
- 如果你想减轻管理 Kubernetes 控制平面的负担,几乎所有的云提供商都有他们的 Kubernetes 托管服务,例如 Google Kubernetes Engine (GKE)、Amazon Elastic Kubernetes Service (EKS)、Azure Kubernetes Service (AKS) 和 IBM Kubernetes Service (IKS)。
- 如果你只是想要一个学习 Kubernetes 的游乐场,Minikube 和 Kind 可以帮助你在几分钟内启动一个 Kubernetes 集群。
因此,正如您所看到的,您有很多选项可供选择来部署您的第一个 Kubernetes 集群。我将介绍使用 kubeadm 在 CentOS 8 服务器上安装 Kubernetes CLuster 的步骤。
安装 Pod 网络插件(weave-net)
您必须部署基于容器网络接口 (CNI) 的容器网络插件,以便您的 Pod 可以相互通信。在安装网络之前,群集 DNS (CoreDNS) 不会启动。
存在不同的项目来提供 Kubernetes 网络支持,这需要支持以下类型的网络:
- container-to-container
- pod-to-pod
- pod-to-service
- external-to-service
常见的 Pod 网络插件:
- Flannel:这是集群节点之间的第 3 层 IPv4 网络,可以使用多种后端机制,例如 VXLAN
- Weave:支持 CNI 的 Kubernetes 集群的通用附加组件
- Calico:使用 IP 封装的第 3 层网络解决方案,用于 Kubernetes、Docker、OpenStack、OpenShift 等
- AWS VPC: AWS环境常用的网络插件
提示:
要获取安装不同 Pod 网络附加插件的步骤列表,您可以按照官方指南进行操作。
我们将为我们的 Kubernetes 集群使用 weave-net 网络插件。您必须允许流量在所有节点上流经 TCP 6783 和 UDP 6783/6784,这些节点是 Woven 的控制端口和数据端口。
[root@controller ~]# firewall-cmd --add-port 6783/tcp --add-port 6783/udp --add-port 6784/udp --permanent[root@controller ~]# firewall-cmd --reload[root@controller ~]# firewall-cmd --list-ports6443/tcp 2379-2380/tcp 10250-10252/tcp 6783/tcp 6783/udp 6784/udp[root@worker-1 ~]# firewall-cmd --list-ports10250/tcp 30000-32767/tcp 6783/tcp 6783/udp 6784/udp[root@worker-2 ~]# firewall-cmd --list-ports10250/tcp 30000-32767/tcp 6783/tcp 6783/udp 6784/udp守护程序还使用 TCP 6781/6782 作为指标,但如果您希望从其他主机收集指标,则只需打开此端口。
您可以使用官方指南中的以下命令在控制平面节点上安装 Pod 网络插件:
[root@controller ~]# kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"serviceaccount/weave-net createdclusterrole.rbac.authorization.k8s.io/weave-net createdclusterrolebinding.rbac.authorization.k8s.io/weave-net createdrole.rbac.authorization.k8s.io/weave-net createdrolebinding.rbac.authorization.k8s.io/weave-net createddaemonset.apps/weave-net created每个集群只能安装一个 Pod 网络。
安装 Pod 网络后,您可以通过检查 CoreDNS Pod 是否在 的输出中来确认它是否正常工作。目前,weave-net正在创建容器,因此状态为,而CoreDNS的状态为:Runningkubectl get pods --all-namespacesContainerCreatingPending
[root@controller ~]# kubectl get pods --all-namespacesNAMESPACE NAME READY STATUS RESTARTS AGEkube-system coredns-f9fd979d6-4bdhv 0/1 Pending 0 3m37skube-system coredns-f9fd979d6-nd44t 0/1 Pending 0 3m37skube-system etcd-controller.example.com 1/1 Running 0 3m34skube-system kube-apiserver-controller.example.com 1/1 Running 0 3m34skube-system kube-controller-manager-controller.example.com 1/1 Running 0 3m34skube-system kube-proxy-gcgj4 1/1 Running 0 3m37skube-system kube-scheduler-controller.example.com 1/1 Running 0 3m34skube-system weave-net-kgzwc 0/2 ContainerCreating 0 2s我们还可以使用相同的命令,该命令将提供有关每个命名空间的更多详细信息。几分钟后再次检查状态,所有命名空间都应处于状态:-o wideRunning
[root@controller ~]# kubectl get pods --all-namespaces -o wideNAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESkube-system coredns-f9fd979d6-4bdhv 1/1 Running 0 5m19s 10.32.0.3 controller.example.com <none> <none> kube-system coredns-f9fd979d6-nd44t 1/1 Running 0 5m19s 10.32.0.2 controller.example.com <none> <none> kube-system etcd-controller.example.com 1/1 Running 0 5m16s 192.168.43.48 controller.example.com <none> <none> kube-system kube-apiserver-controller.example.com 1/1 Running 0 5m16s 192.168.43.48 controller.example.com <none> <none> kube-system kube-controller-manager-controller.example.com 1/1 Running 0 5m16s 192.168.43.48 controller.example.com <none> <none> kube-system kube-proxy-gcgj4 1/1 Running 0 5m19s 192.168.43.48 controller.example.com <none> <none> kube-system kube-scheduler-controller.example.com 1/1 Running 0 5m16s 192.168.43.48 controller.example.com <none> <none> kube-system weave-net-kgzwc 2/2 Running 0 104s 192.168.43.48 controller.example.com接下来检查集群的状态,如果您还记得在安装 Pod 网络插件之前处于状态,但现在集群处于状态。NotReadyReady
[root@controller ~]# kubectl get nodesNAME STATUS ROLES AGE VERSIONcontroller.example.com Ready master 85m v1.19.3加入工作节点
要将新节点添加到集群,请通过 SSH 连接到所有工作节点,并以 root 用户身份执行从命令输出中保存的命令:kubeadm joinkubeadm init
~]# kubeadm join 192.168.43.48:6443 --token rdet9b.4pugjes5hwq3aynk --discovery-token-ca-cert-hash sha256:d2408f85e478b5a9927f1fafd89630fb71a1ce07d5e26e0cf4c7ff4320d433a2来自我的一个工作节点的示例输出:
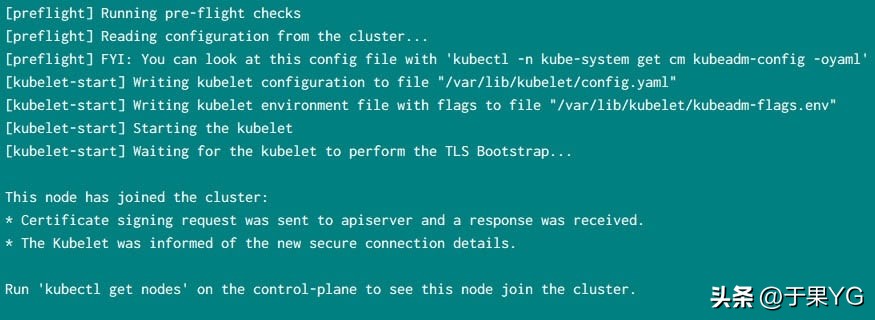
接下来检查节点的状态,它应该处于状态,如果状态显示为,那么您可以检查 pod 的状态,如我在下一个命令中所示:ReadyNotReady
[root@controller ~]# kubectl get nodesNAME STATUS ROLES AGE VERSIONcontroller.example.com Ready master 161m v1.19.3worker-2.example.com NotReady 17m v1.19.3检查所有可用命名空间中 Pod 的状态,以确保新创建的 Pod 正在运行,当前正在为我们启动 join 命令的工作节点上的各个 Pod 创建容器:
[root@controller ~]# kubectl get pods --all-namespaces -o wideNAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESkube-system coredns-f9fd979d6-4bdhv 1/1 Running 0 27m 10.32.0.2 controller.example.com <none> <none>kube-system coredns-f9fd979d6-nd44t 1/1 Running 0 27m 10.32.0.3 controller.example.com <none> <none>kube-system etcd-controller.example.com 1/1 Running 0 27m 192.168.43.48 controller.example.com <none> <none>kube-system kube-apiserver-controller.example.com 1/1 Running 0 27m 192.168.43.48 controller.example.com <none> <none>kube-system kube-controller-manager-controller.example.com 1/1 Running 0 27m 192.168.43.48 controller.example.com <none> <none>kube-system kube-proxy-ffxx6 0/1 ContainerCreating 0 102s 192.168.43.50 worker-2.example.com <none> <none>kube-system kube-proxy-gcgj4 1/1 Running 0 27m 192.168.43.48 controller.example.com <none> <none>kube-system kube-scheduler-controller.example.com 1/1 Running 0 27m 192.168.43.48 controller.example.com <none> <none>kube-system weave-net-kgzwc 2/2 Running 0 22m 192.168.43.48 controller.example.com <none> <none>kube-system weave-net-wjzb7 0/2 ContainerCreating 0 102s 192.168.43.50 worker-2.example.com <none> <none>同样,添加到群集:worker-1.example.com
[root@worker-1 ~]# kubeadm join 192.168.43.48:6443 --token rdet9b.4pugjes5hwq3aynk --discovery-token-ca-cert-hash sha256:d2408f85e478b5a9927f1fafd89630fb71a1ce07d5e26e0cf4c7ff4320d433a2[preflight] Running pre-flight checks[preflight] Reading configuration from the cluster...[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"[kubelet-start] Starting the kubelet[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...This node has joined the cluster:* Certificate signing request was sent to apiserver and a response was received.* The Kubelet was informed of the new secure connection details.Run 'kubectl get nodes' on the control-plane to see this node join the cluster.添加两个工作节点后,所有 Pod 都应处于运行状态:
[root@controller ~]# kubectl get pods --all-namespaces -o wideNAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESkube-system coredns-f9fd979d6-4bdhv 1/1 Running 0 27m 10.32.0.2 controller.example.com <none> <none>kube-system coredns-f9fd979d6-nd44t 1/1 Running 0 27m 10.32.0.3 controller.example.com <none> <none>kube-system etcd-controller.example.com 1/1 Running 0 27m 192.168.43.48 controller.example.com <none> <none>kube-system kube-apiserver-controller.example.com 1/1 Running 0 27m 192.168.43.48 controller.example.com <none> <none>kube-system kube-controller-manager-controller.example.com 1/1 Running 0 27m 192.168.43.48 controller.example.com <none> <none>kube-system kube-proxy-ffxx6 1/1 Running 0 17m 192.168.43.50 worker-2.example.com <none> <none>kube-system kube-proxy-gcgj4 1/1 Running 0 27m 192.168.43.48 controller.example.com <none> <none>kube-system kube-proxy-xfzl7 1/1 Running 0 13m 192.168.43.49 worker-1.example.com <none> <none>kube-system kube-scheduler-controller.example.com 1/1 Running 0 27m 192.168.43.48 controller.example.com <none> <none>kube-system weave-net-62bq8 1/2 Running 3 13m 192.168.43.49 worker-1.example.com <none> <none>kube-system weave-net-kgzwc 2/2 Running 0 22m 192.168.43.48 controller.example.com <none> <none>kube-system weave-net-wjzb7 2/2 Running 1 17m 192.168.43.50 worker-2.example.com <none> <none>还要验证控制器节点上的节点状态:
[root@controller ~]# kubectl get nodesNAME STATUS ROLES AGE VERSIONcontroller.example.com Ready master 53m v1.19.3worker-1.example.com Ready 38m v1.19.3worker-2.example.com Ready 42m v1.19.3所以现在所有节点的状态都处于状态。Ready
故障 排除
在本节中,我将分享我在设置 kubeadm 集群时遇到的问题及其解决方案:
错误:失败:打开 /run/systemd/resolve/resolv.conf:没有这样的文件或目录”
我在缺少此目录“”的工作节点上收到此错误。以下是日志中的完整错误片段:/run/systemd/resolve
Error syncing pod 502bb214-5a88-4e72-b30b-7332e51642e3 ("weave-net-zkdbq_kube-system(502bb214-5a88-4e72-b30b-7332e51642e3)"), skipping: failed to "CreatePodSandbox" for "weave-net-zkdbq_kube-system(502bb214-5a88-4e72-b30b-7332e51642e3)" with CreatePodSandboxError: "GeneratePodSandboxConfig for pod \"weave-net-zkdbq_kube-system(502bb214-5a88-4e72-b30b-7332e51642e3)\" failed: open /run/systemd/resolve/resolv.conf: no such file or directory"一些Linux发行版(例如Ubuntu)默认使用本地DNS解析器(systemd解析)。系统解析的移动并替换为存根文件,在解析上游服务器中的名称时,这可能会导致致命的转发循环。这可以通过使用 kubelet 的标志指向正确的标志来手动修复(使用 systemd 解析,这是 )。Kubeadm 会自动检测 systemd 解析,并相应地调整 kubelet 标志。/etc/resolv.conf--resolv-confresolv.conf/run/systemd/resolve/resolv.conf
要解决此问题,请确保在相应的节点上运行:systemd-resolved
[root@worker-2 ~]# systemctl status systemd-resolved● systemd-resolved.service - Network Name Resolution Loaded: loaded (/usr/lib/systemd/system/systemd-resolved.service; disabled; vendor preset: disabled) Active: active (running) since Wed 2020-11-11 11:18:08 IST; 1s ago Docs: man:systemd-resolved.service(8) https://www.freedesktop.org/wiki/Software/systemd/resolved https://www.freedesktop.org/wiki/Software/systemd/writing-network-configuration-managers https://www.freedesktop.org/wiki/Software/systemd/writing-resolver-clients Main PID: 16964 (systemd-resolve) Status: "Processing requests..." Tasks: 1 (limit: 18135) Memory: 2.8M CGroup: /system.slice/systemd-resolved.service └─16964 /usr/lib/systemd/systemd-resolvedNov 11 11:18:08 worker-2.example.com systemd[1]: Starting Network Name Resolution...如果它未处于运行状态,则手动启动服务:
[root@worker-2 ~]# systemctl start systemd-resolved并启用以自动启动此服务:
[root@worker-2 ~]# systemctl enable systemd-resolvedCreated symlink /etc/systemd/system/dbus-org.freedesktop.resolve1.service → /usr/lib/systemd/system/systemd-resolved.service.Created symlink /etc/systemd/system/multi-user.target.wants/systemd-resolved.service → /usr/lib/systemd/system/systemd-resolved.service.错误:工作器节点将崩溃循环回退显示为状态
以下是来自工作节点的日志:
Nov 11 11:26:05 worker-2.example.com kubelet[17992]: W1111 11:26:05.368907 17992 cni.go:239] Unable to update cni config: no networks found in /etc/cni/net.dNov 11 11:26:07 worker-2.example.com kubelet[17992]: E1111 11:26:07.827786 17992 kubelet.go:2103] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized这些可能是通用消息,可能意味着差异问题,首先确保 Linux 服务器上使用的默认路由用于与 Kubernetes 群集节点通信,例如,这里我的默认网络通过 192.168.43.0 子网路由,而我的群集节点也可以通过同一网络访问。
~]# ip routedefault via 192.168.43.1 dev eth1 proto static metric 10110.0.2.0/24 dev eth0 proto kernel scope link src 10.0.2.15 metric 10010.32.0.0/12 dev weave proto kernel scope link src 10.36.0.0172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown192.168.43.0/24 dev eth1 proto kernel scope link src 192.168.43.49 metric 101192.168.122.0/24 dev virbr0 proto kernel scope link src 192.168.122.1 linkdown如果您配置了多个默认路由(下面的示例输出),那么您将在 kubernetes 控制节点初始化阶段使用。must specify the address
~]# ip routedefault via 10.0.2.2 dev eth0 proto dhcp metric 100default via 192.168.43.1 dev eth1 proto static metric 10110.0.2.0/24 dev eth0 proto kernel scope link src 10.0.2.15 metric 100172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown...在我的一次尝试中,我在Oracle VirtualBox中为我的Kubernetes集群使用了仅主机网络。因此,在控制节点初始化阶段,我使用了:
kubeadm init --apiserver-advertise-address=<control_node_ip>由于 kubeadm 使用与默认网关关联的网络接口来设置此特定控制平面节点的 API 服务器的通告地址。因此,如果我们使用不同的网络进行内部通信,则必须指定--apiserver-advertise-address=<ip-address>
使用此配置,初始化成功,但后来我在将工作节点加入 Kubernetes 集群后遇到了同样的错误。后来经过大量调试,我找到了这个解决了这个问题的 github 页面。事实证明,iptables 中不允许使用 kubernetes 服务使用的默认子网(这可能会在较新版本中修复)。10.96.0.1
[root@controller ~]# kubectl get services --all-namespacesNAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEdefault kubernetes ClusterIP 10.96.0.1 443/TCP 4h23mkube-system kube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP,9153/TCP 4h23m因此,要启用此功能,我们必须在所有节点上添加以下规则。但是只有在将工作节点添加到集群并创建可以使用“”验证的容器后,才应添加此规则,否则您将获得”kubectl get pods --all-namespaces -o wideiptables: Index of insertion too big."
[root@controller ~]# iptables -t nat -I KUBE-SERVICES -d 10.96.0.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE-MARK-MASQ然后重新启动服务以立即激活更改,或者您也可以等待 kubelet 自动检测新更改kubelet
~]# systemctl restart kubelet.现在应该正确添加节点,您可以使用以下命令进行验证:
[root@controller ~]# kubectl get nodesNAME STATUS ROLES AGE VERSIONcontroller.example.com Ready master 4h28m v1.19.3worker-2.example.com Ready 4h22m v1.19.3如果这些更改适用于您的问题,则只需执行后续步骤即可永久更改。
现在,这些更改不会在重新启动后持续存在,因此我们将现有的 iptables 规则保存到新文件中。我正在使用 ,但您可以为此文件选择任何其他位置和名称:/etc/my-iptables-rules
~]# iptables-save > /etc/my-iptables-rules接下来创建一个 systemd 单元文件,该文件将在重新启动后执行 iptables 规则的恢复:
~]# cat /etc/systemd/system/my-iptables.service[Unit]Description=my-iptables - custom iptables daemonBefore=network-pre.targetWants=network-pre.targetAfter=kubelet.serviceConflicts=iptables.service firewalld.service ip6tables.service ebtables.service ipset.service[Service]Type=oneshotExecStart=/usr/sbin/iptables-restore -n /etc/my-iptables-rulesRemainAfterExit=yes[Install]WantedBy=multi-user.target加载更改:
~]# systemctl daemon-reload在这里,我们使用 systemd 服务文件执行已保存的 iptables 规则的恢复。启用该服务以使其在每次重新启动后运行:
~]# systemctl enable my-iptablesCreated symlink /etc/systemd/system/multi-user.target.wants/my-iptables.service → /etc/systemd/system/my-iptables.service.接下来启动服务并检查状态以确保它已正确启动:
~]# systemctl start my-iptables ~]# systemctl status my-iptables● my-iptables.service - my-iptables - custom iptables daemon Loaded: loaded (/etc/systemd/system/my-iptables.service; disabled; vendor preset: disabled) Active: active (exited) since Thu 2020-11-26 11:41:50 IST; 1s ago Process: 11105 ExecStart=/usr/sbin/iptables-restore -n /etc/my-iptables-rules (code=exited, status=0/SUCCESS) Main PID: 11105 (code=exited, status=0/SUCCESS)Nov 26 11:41:50 worker-2.example.com systemd[1]: Starting my-iptables - custom iptables daemon...Nov 26 11:41:50 worker-2.example.com systemd[1]: Started my-iptables - custom iptables daemon.因此,我们的服务已正常启动。现在,新添加的iptables规则将在每次重新启动后自动添加。
注意:
只有在 kubernetes 的上游版本中未修复之前,才需要此黑客来添加新的 iptables 规则
在所有群集节点上重复这些步骤并重新启动 kubelet 服务
错误:核心 DNS 停滞在挂起/失败状态
通常,在控制节点初始化步骤之后,CoreDNS 处于挂起状态。稍后,一旦我们安装了 kubernetes 网络插件,CoreDNS 命名空间状态应该更改为,但如果它仍处于挂起/失败状态,则需要检查一些事项:Running
使用 kubectl get pods 命令来验证 DNS pod 是否正在运行。
[root@controller ~]# kubectl get pods --namespace=kube-system -l k8s-app=kube-dnsNAME READY STATUS RESTARTS AGEcoredns-f9fd979d6-4bdhv 1/1 Running 0 4h53mcoredns-f9fd979d6-nd44t 1/1 Running 0 4h53m检查 DNS 容器的错误日志。
kubectl logs --namespace=kube-system -l k8s-app=kube-dns验证 DNS 服务是否已启动并正在运行,或者您可以按照官方故障排除指南调试服务
[root@controller ~]# kubectl get svc --namespace=kube-systemNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP,9153/TCP 4h54m日志文件位置
有两种类型的系统组件:在容器中运行的组件和不在容器中运行的组件。例如:
- Kubernetes 调度器和 kube-proxy 在一个容器中运行。
- kubelet 和容器运行时(例如 Docker)不会在容器中运行。
在装有 systemd 的机器上,kubelet 和容器运行时会写入 journald。否则,它们将写入目录中的文件。容器内的系统组件始终写入目录中的文件,绕过默认日志记录机制。.log/var/log.log/var/log
启用 Shell 自动完成(可选)
现在这不是强制性步骤,但只需按键盘上的 TAB 键即可使用 kubectl 获取支持的选项列表很有用。kubectl 为 Bash 和 Zsh 提供了自动完成支持,可以为您节省大量键入时间。要启用自动完成,我们必须首先在相应的节点上安装 bash-complete。由于我们大部分时间都在使用我们的主节点,因此我们将仅在控制器节点上安装此软件包:
[root@controller ~]# dnf -y install bash-completion接下来执行 kubectl 完成 bash 以获取将为 kubectl 执行自动完成的脚本,这将在控制台上给出一个长输出
[root@controller ~]# kubectl completion bash我们将此命令的输出保存到根用户的 ~/.bashrc 中。
[root@controller ~]# kubectl completion bash >> ~/.bashrc如果您希望所有其他用户都可以使用它,则可以在 /etc/bash_completion.d/ 中创建一个新文件并保存内容:
[root@controller ~]# kubectl completion bash >> /etc/bash_completion.d/kubectl接下来重新加载您的 shell,现在您可以输入并按 TAB,这应该为您提供支持的选项列表:kubectl
[root@controller ~]# kubectl <press TAB on the keyboard>alpha attach completion create edit kustomize plugin run uncordonannotate auth config delete exec label port-forward scale versionapi-resources autoscale convert describe explain logs proxy set waitapi-versions certificate cordon diff expose options replace taintapply cluster-info cp drain get patch rollout top结论
在这个 Kubernetes 教程中,我们学习了使用 Kubeadm 部署多节点 Kubernetes 集群的步骤。容器运行时和网络附加组件有不同的选项可供选择,在本文中,我们使用 Docker CE 作为我们的运行时,但如果您计划选择任何其他软件,则可能需要其他配置。同样,对于网络附加组件,我们使用了weave-net插件,但您可以选择使用其他插件,但配置步骤可能会再次有所不同,您必须参考相应的官方文档。
【打完收工,溜了!溜了!溜了!】
欢迎各位小伙伴关注、点赞、评论、转发,你的关注和转发是我最大的动力!





















 1
1







